Training graphs
Four graphs update as training progresses: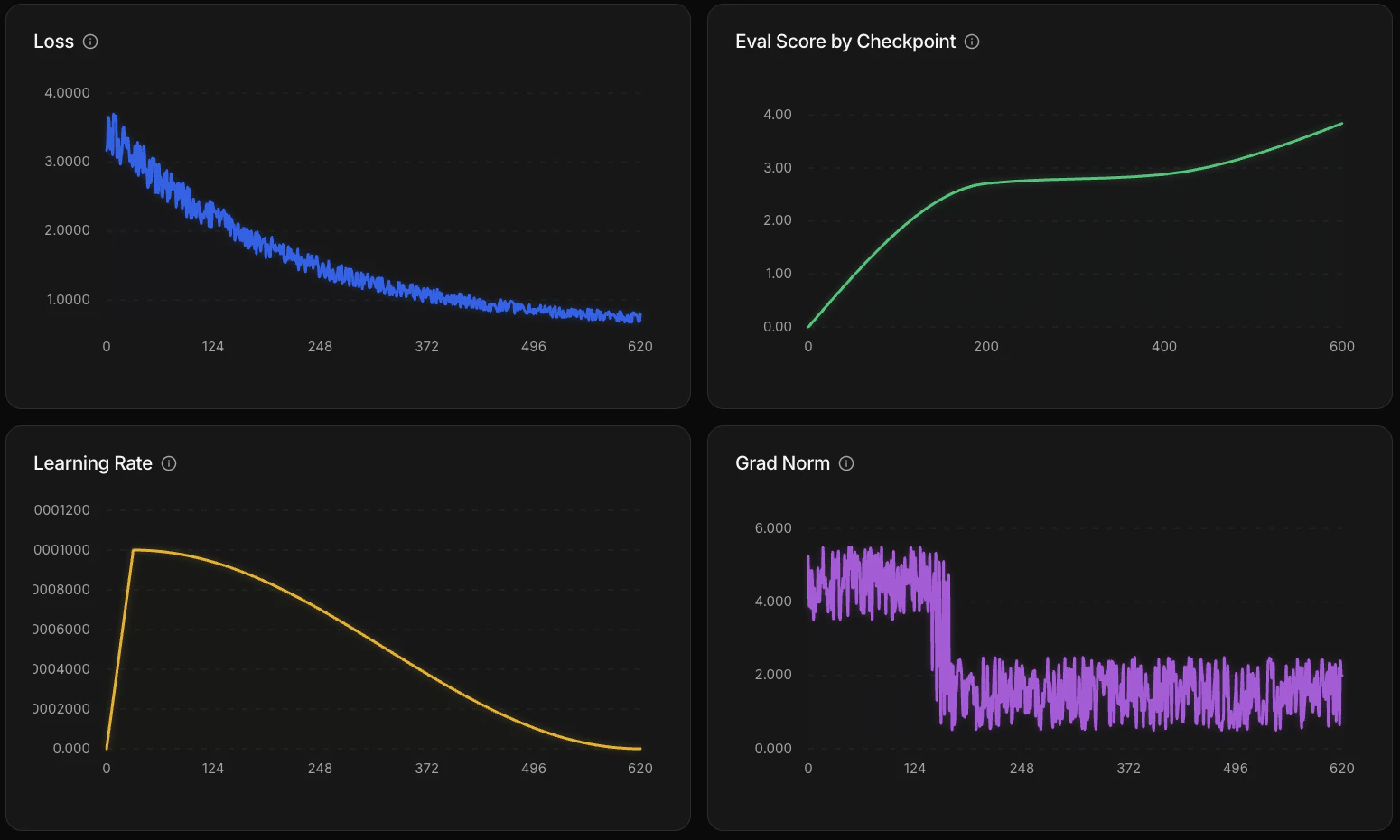
Training graphs showing loss, learning rate, gradient norm, and eval score during an active run.
Evaluations
The platform runs evaluations at three points during a training job:- Before training — establishes a baseline score for the model before any weight updates
- During training — at each checkpoint, the model runs your eval dataset and an LLM judge scores the outputs using your rubric
- After training — a final evaluation on the completed model
Checkpoints
Training saves checkpoints at regular intervals. If a run fails after a checkpoint, it can be resumed from the last saved state rather than starting over.Logs
The Logs tab shows output from all GPUs during training. Use it to debug issues or see what’s happening under the hood. You can filter logs by type —warn, error, and others — to focus on what matters.