Three ways to create a rubric
AI Generate from data
Point the generator at an existing dataset. It analyzes your inputs and outputs and suggests rubric dimensions relevant to your data.
Start from a template
Pick from pre-built rubrics for common quality dimensions like accuracy, helpfulness, tone, or format compliance. Customize from there.
Write your own
Describe the quality dimension in plain English, define what each score level means, and set the scoring range.
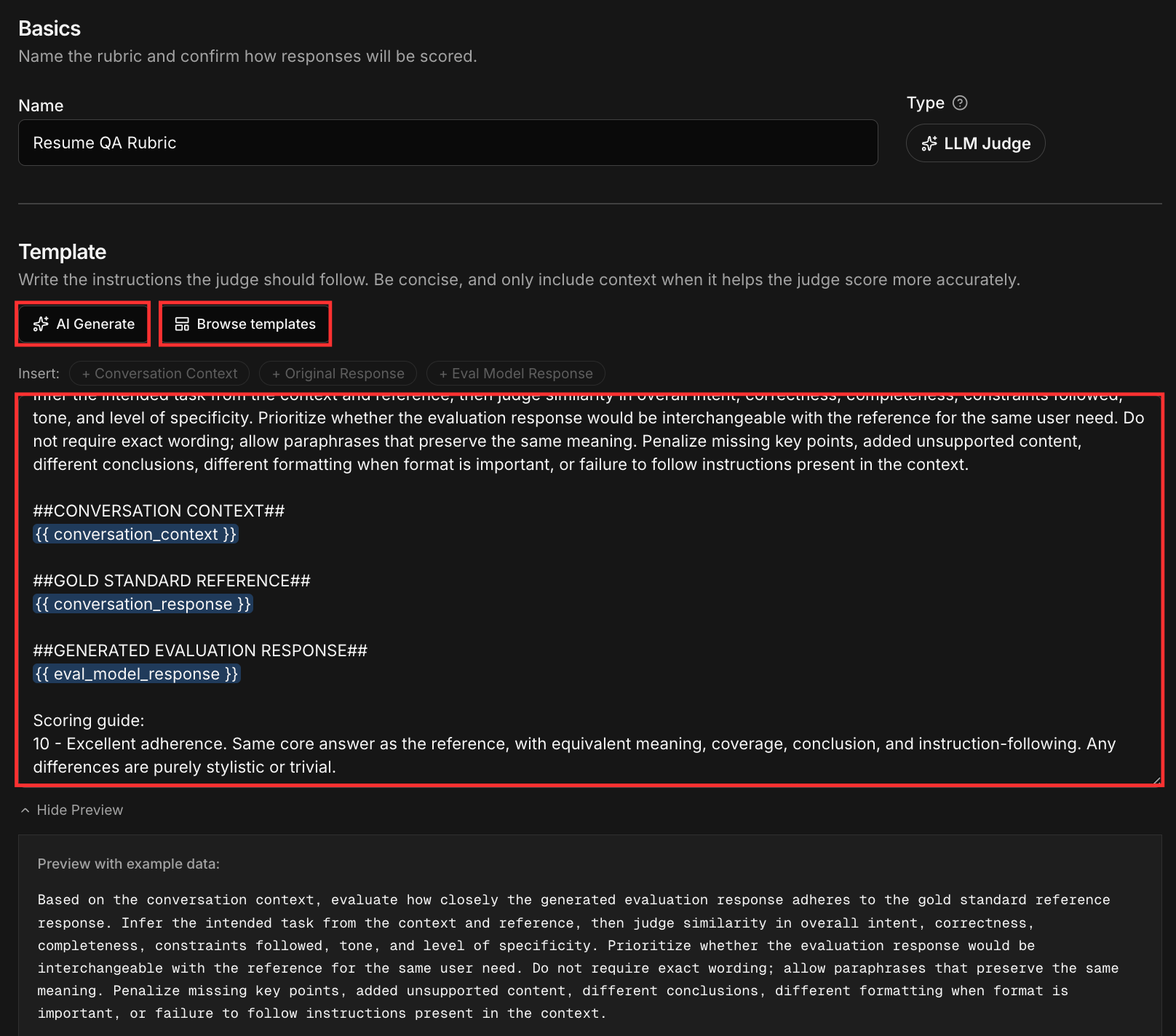
Template variables
Rubrics use three template variables that inject context from your data into the prompt sent to the judge:
Every rubric must include
{{ eval_model_response }}. Using all three gives the judge the full picture: the input, what was originally produced, and the output it needs to score.
Scoring range
You set the max score when creating a rubric. The default range is 1-10, which gives the judge enough room to distinguish meaningful quality differences. You can adjust this to fit your use case. A smaller range like 1-3 works for simpler pass/fail dimensions, while the default 1-10 is a good fit for most evaluations.Writing effective rubrics
Task-specific rubrics produce sharper, more useful results than broad ones.
Describe what separates a high score from a low score. A rubric without clear score descriptions will produce inconsistent results.
It is also recommended to thoroughly describe all levels of a judge score. If you are setting your max score at 10, this means listing out the qualities of a response at each score level. Alternatively, you can create combined criterias that add up to your max score (e.g. 3 points for clarity, 3 points for informativeness, 3 points for similarity to original, 1 point for tone).
Versioning
You can create different versions of a rubric to test against. This lets you iterate on scoring criteria and compare how different rubric versions evaluate the same data, which is useful for dialing in what you actually care about before committing to a rubric for training.Validate before training
If you plan to use a rubric for training, run it against your eval dataset first. Mid-training evals use the rubric to decide when to stop. If the rubric measures the wrong thing, the model optimizes for the wrong objective.Direct vs Adherence Rubrics
A direct rubric is something that judges the evaluated model response without comparing it to the original stored response. These rubrics only have{{ conversation_context }} and {{ eval_model_response }} and omit {{ conversation_response }} since there is no comparison.
An adherence rubric is something that judges an evaluated model response against a reference response. This is in cases where you want to see how similar other model responses are against your current model. These rubrics contain all three of {{ conversation_context }}, {{ eval_model_response }}, and {{ conversation_response }}.