Start the demo project
If you haven’t already, create the demo project:- From the dashboard, navigate to the Learn page (or the Create a Project page).
- Find Customer Support Chatbot and click Start with demo project.
Run an eval
1
Navigate to Evals
Open your Customer Support Chatbot project and go to the Evals tab. Click New Eval.
2
Select the rubric and dataset
The demo project’s rubric and the 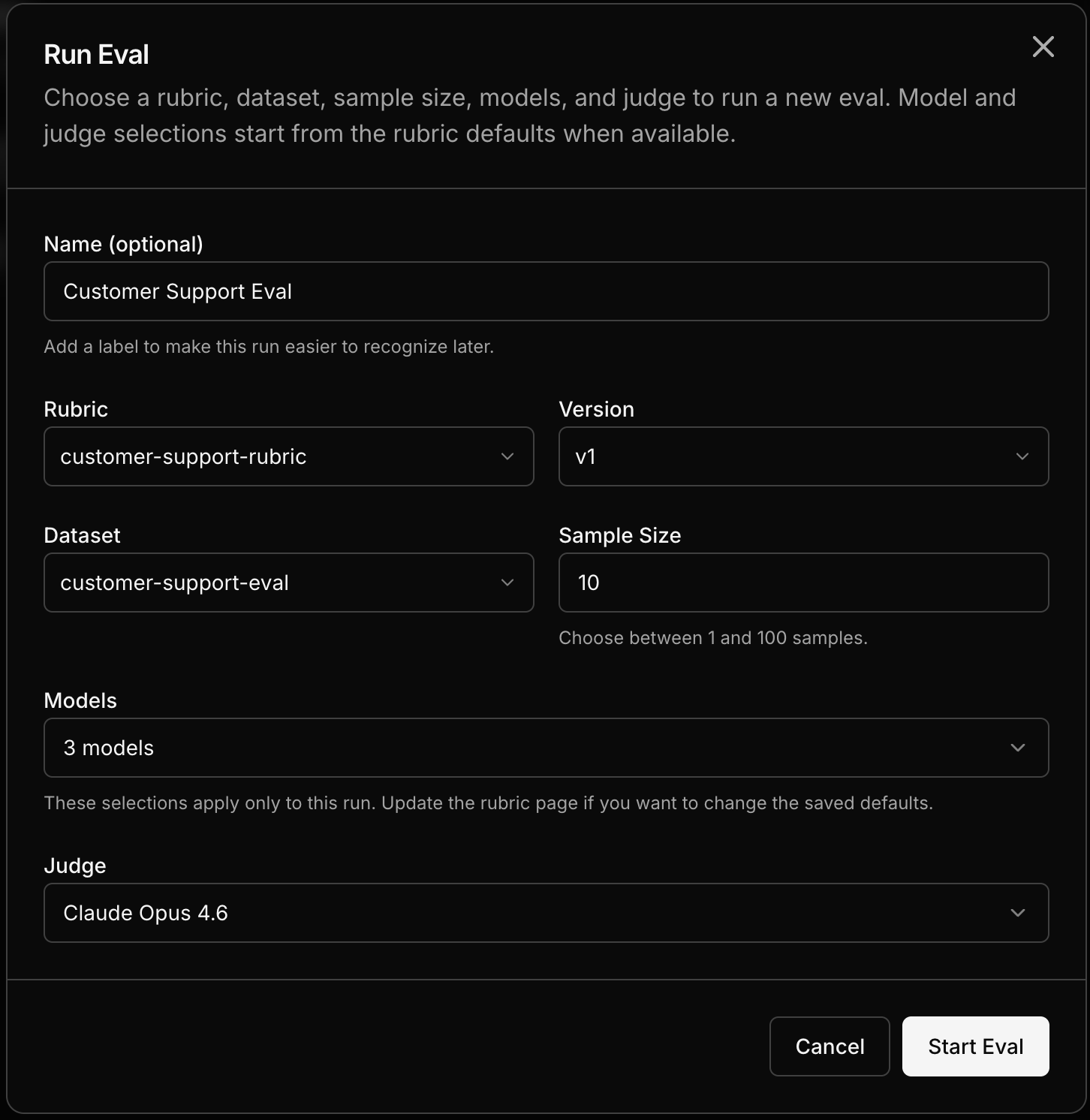
customer-support-eval dataset are already available in your project. Select them.3
Pick models to compare
Choose two or more models to evaluate. You can pick any combination from the model catalog — OpenAI, Anthropic, open-source, or any other available model. For a quick comparison, try picking a large model and a smaller one to see how they stack up.
4
Run the eval
Click Run. Each sample from the dataset is sent to each model, and an LLM judge scores every response against the rubric.
5
Compare the results
When the eval completes, the comparison view shows side-by-side scores across all models and samples. Look at overall scores to see which model wins, and drill into individual samples to understand where models differ.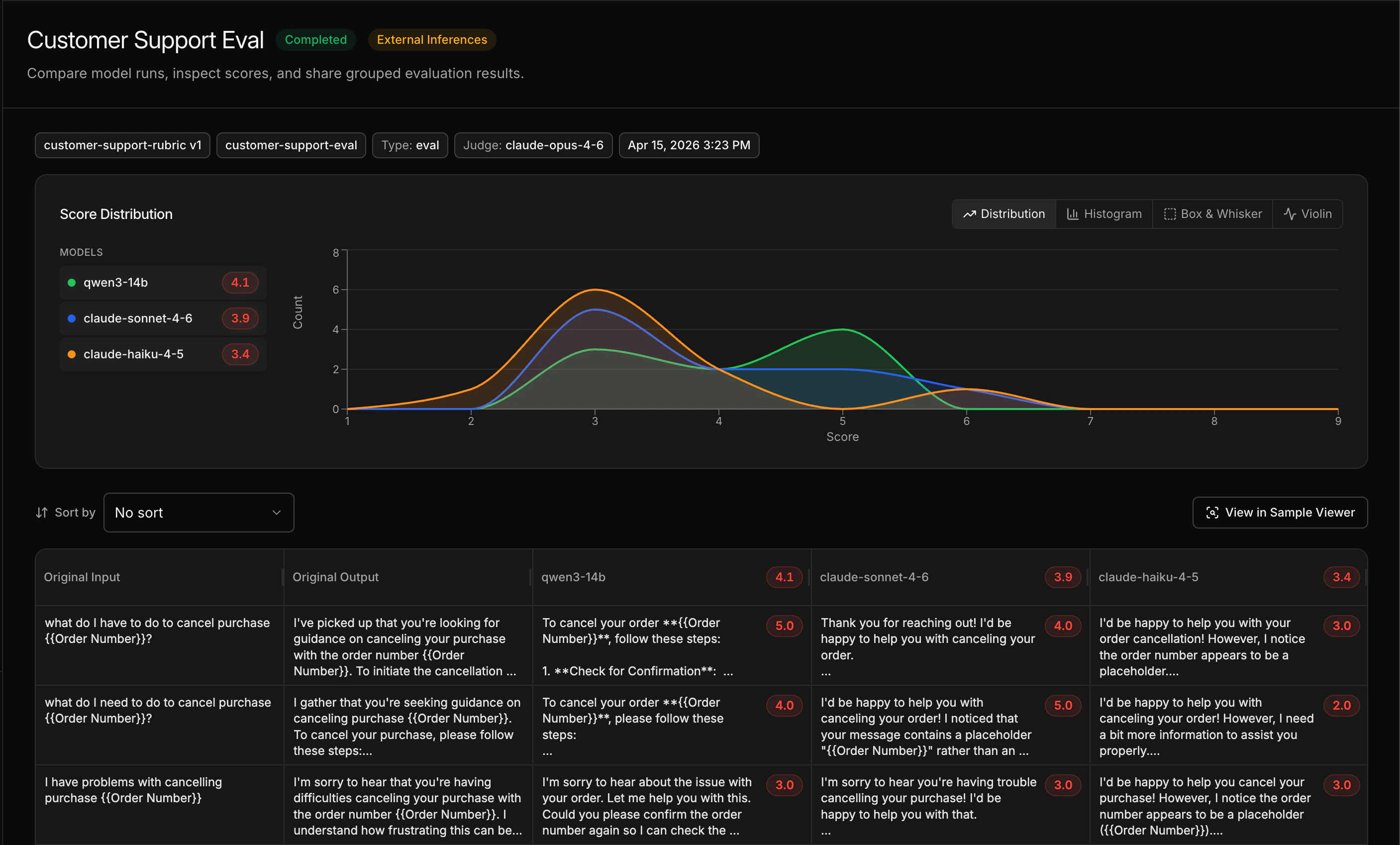
What you just learned
- Rubrics define your quality bar in plain English — the LLM judge uses them to score outputs
- Evals run your data through multiple models and score the results, giving you a data-driven comparison
- You can re-run evals anytime — after changing the rubric, adding models, or later after training a custom model to see how it compares
Next steps
Train a custom model
Use the same demo project to train and deploy a model.
Write a rubric
Learn how to write your own rubrics for your specific use case.
Read the results
Deep dive on interpreting the comparison view.
Build a dataset
Create datasets from your own data — captured traffic or uploaded files.