Lifecycle operations
- Start — bring a stopped deployment back online
- Stop — take the deployment offline
- Delete — remove the deployment entirely
Scaling
By default, your model deploys on a single dedicated GPU. If you need additional GPUs or auto-scaling, reach out to our team.Monitoring
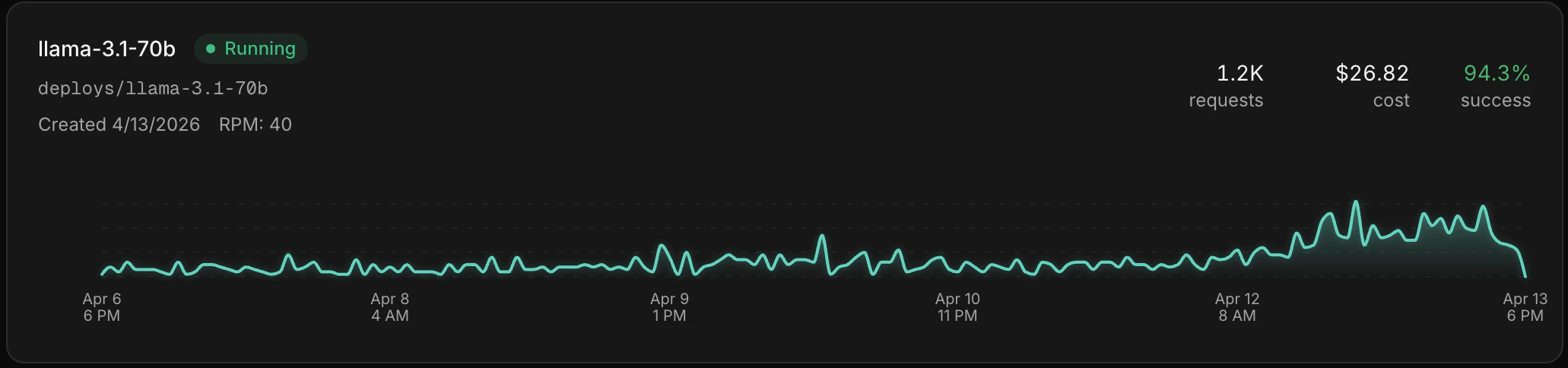
Once your deployment is live, click into it from the Deployments page to see metrics and individual inference calls. You get the same Gateway experience — latency, error rates, token usage, and full request/response payloads — scoped to that deployment.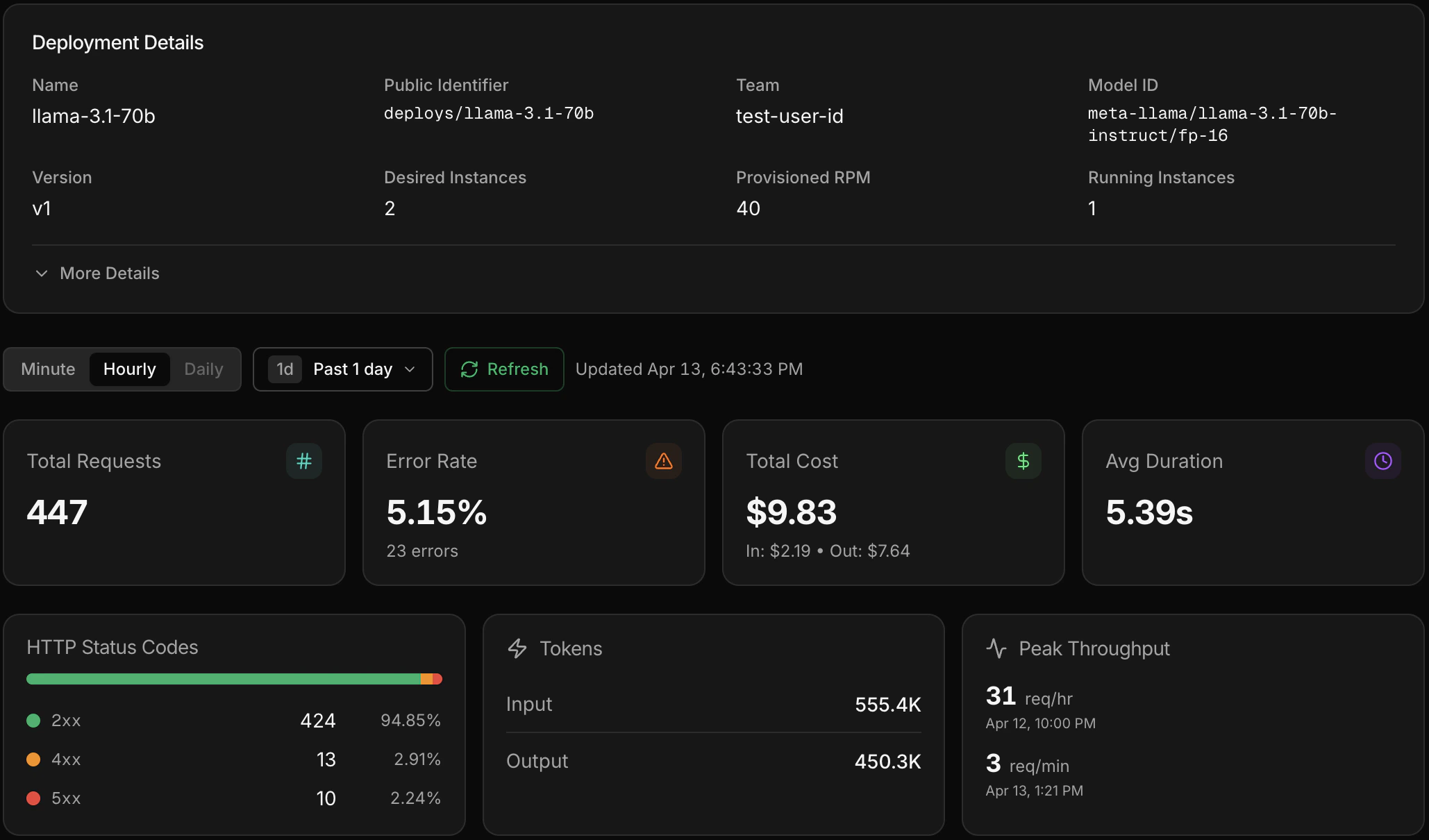
Deployment detail page showing metrics and inference calls.
The loop continues
Your custom model is live. Use Gateway to watch its production performance, run evals to catch regressions, and train the next version when you’re ready.Gateway
Monitor production traffic.
Eval
Catch quality regressions.
Train
Build the next version.