This guide uses the hosted version of HALO on the Catalyst dashboard. Want to run the same loop entirely on your own machine, with traces that never leave your laptop and no account required? See HALO Desktop: Optimize an Agent End to End on Your Machine.
context-labs/SearchAgentDemo is a small search agent that comes already instrumented with Catalyst tracing. You get traces into your project (upload a pre-run dataset or generate your own), run HALO (our open-source agent-loop optimizer) over them, and then connect the MCP server so your coding agent pulls the HALO report and edits the repo for you. The repo even ships with a handful of deliberate, documented flaws, so HALO has something real to find and you get to watch it close the loop.
The only hard requirement is a free Inference account. We even publish a pre-run trace dataset, so you can be looking at a HALO report in a couple of minutes without running the agent at all. And when you do want to generate your own, the agent has a mock-search mode, so you don’t even need a Tavily key.
Pick your language. The demo ships in two behaviorally identical flavors:
context-labs/SearchAgentDemo (Python) and context-labs/SearchAgentDemoTS (TypeScript). Same tools, same deliberate flaws, same dataset, same traces, same HALO findings. Use the language tabs in each step; everything between the steps (the dashboard, HALO, and MCP) is identical.Before you start
You need:- A free Inference account.
- An API key from the dashboard.
- For the Python repo:
uvinstalled (the repo uses it for dependency management), plusgitand Python 3.11+. For the TypeScript repo:buninstalled, plusgit. - A coding agent with MCP support for the last few steps (Claude Code, Cursor, or any MCP client).
- A Tavily API key for real web search. Without one, run the agent in
--mock-searchmode. Traces still flow, they’re just more uniform.
Step 1: Clone the demo repo
agentId: traceable-search-agent), and the Tavily calls inside the tools add manual RETRIEVER spans, so the traces have genuine structure for HALO to dig into.
Step 2: Install and configure
Install dependencies:.env from the example:
.env and paste in one thing, your Inference API key:
gpt-4.1-mini (cheap, reliable tool-calling), so unless you want to change it, your only edit is pasting the key.
One key, two jobs.
INFERENCE_API_KEY authenticates the agent’s model calls against Inference’s OpenAI-compatible endpoint (https://api.inference.net/v1) and is copied into CATALYST_OTLP_TOKEN so traces flow to https://telemetry.inference.net. Both are wired up for you, no other configuration needed. Prefer a different OpenAI-compatible provider? Set INFERENCE_BASE_URL and INFERENCE_API_KEY to theirs.Step 3: Get traces into your project
HALO needs a body of traces to analyze. There are two ways to get them, and they’re not exclusive:- Option A, upload the pre-run dataset (fastest). We already ran the agent across the full query set many times and published the resulting traces. Download once, upload into your project, and you’re at HALO in two minutes with no model or search spend.
- Option B, generate your own. Run the repo locally to produce fresh traces. Slower and costs a little, but they’re your runs, and you can keep generating after you change the code.
Option A: Upload the pre-run dataset
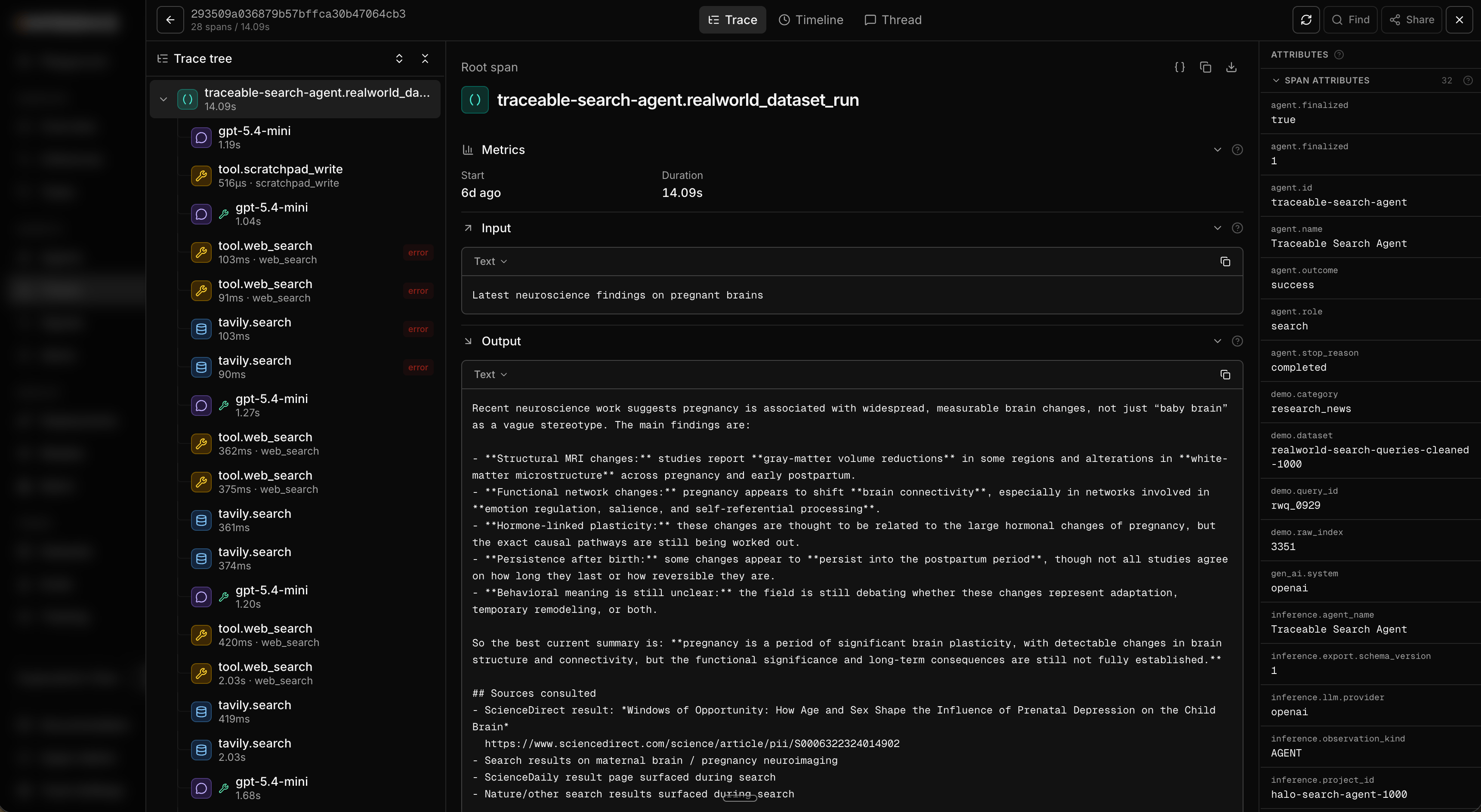
The repo ships the pre-run dataset with it, no download needed. We ran the agent across the full query set many times and committed the resulting traces as a gzipped OTLP JSONL file atdata/search-agent-demo-traces.jsonl.gz (~20 MB). It’s roughly 1,000 traces with real search variance across the whole query set, far more, and more varied, than you’d want to generate by hand. Because they came from this repo, they already carry the traceable-search-agent identity and the same span shape, so they behave exactly like runs you’d produce yourself.
Decompress it first (expands to one ~200 MB JSONL file). The -k flag keeps the original .gz around:
data/search-agent-demo-traces.jsonl ready to upload. Two ways:
From the dashboard. Open the Traces tab, click imports, and select the file. The dashboard validates it, processes it, and the traces show up in the table when it’s done.
inf trace upload does the same thing and waits for processing to finish:
Uploading traces is a dashboard or CLI action. The MCP server reads, exports, and analyzes traces (it doesn’t upload them), so do the import here, then drive HALO over the uploaded traces from your coding agent in Steps 5–7.
Option B: Generate your own traces
The repo is a command-line tool. There’s no web UI and no server to start. You run it from the terminal, and every run does two things: it answers the query, and it ships a full trace to Catalyst. Those traces are the data HALO analyzes, so “generating data” just means running the agent a handful of times. You view and analyze it afterward in the dashboard (Step 4 on). Two ways to run it:search-agent "<query>"runs one query, one trace. Good for a smoke test.search-agent-batchruns a slice of the bundled 50-query dataset, one trace per row. This is how you build up enough varied runs for a meaningful HALO report.
session_id. That same session_id shows up in the dashboard so you can find the run.
Now seed a batch. HALO works best with repeated behavior across varied tasks, so the repo ships a 50-query starter dataset. Run a slice of it:
dataset-q001 and trace attributes for demo.query_id, demo.category, and demo.dataset, so the runs group and filter cleanly. Run a few different slices to build up variety:
Command-line options
Command-line options
Both commands take the same core flags (drop the
-- value examples in as needed):So a free, no-key run of five dataset rows is
search-agent-batch --limit 5 --mock-search, and a real-search slice starting at row 20 is search-agent-batch --start 20 --limit 5.Step 4: See your traces in the dashboard
Open the Agents tab in the dashboard. Whether you uploaded the pre-run dataset or generated your own, the traces roll up under a single agent, Traceable Search Agent (traceable-search-agent), because every span carries that stable agentId.
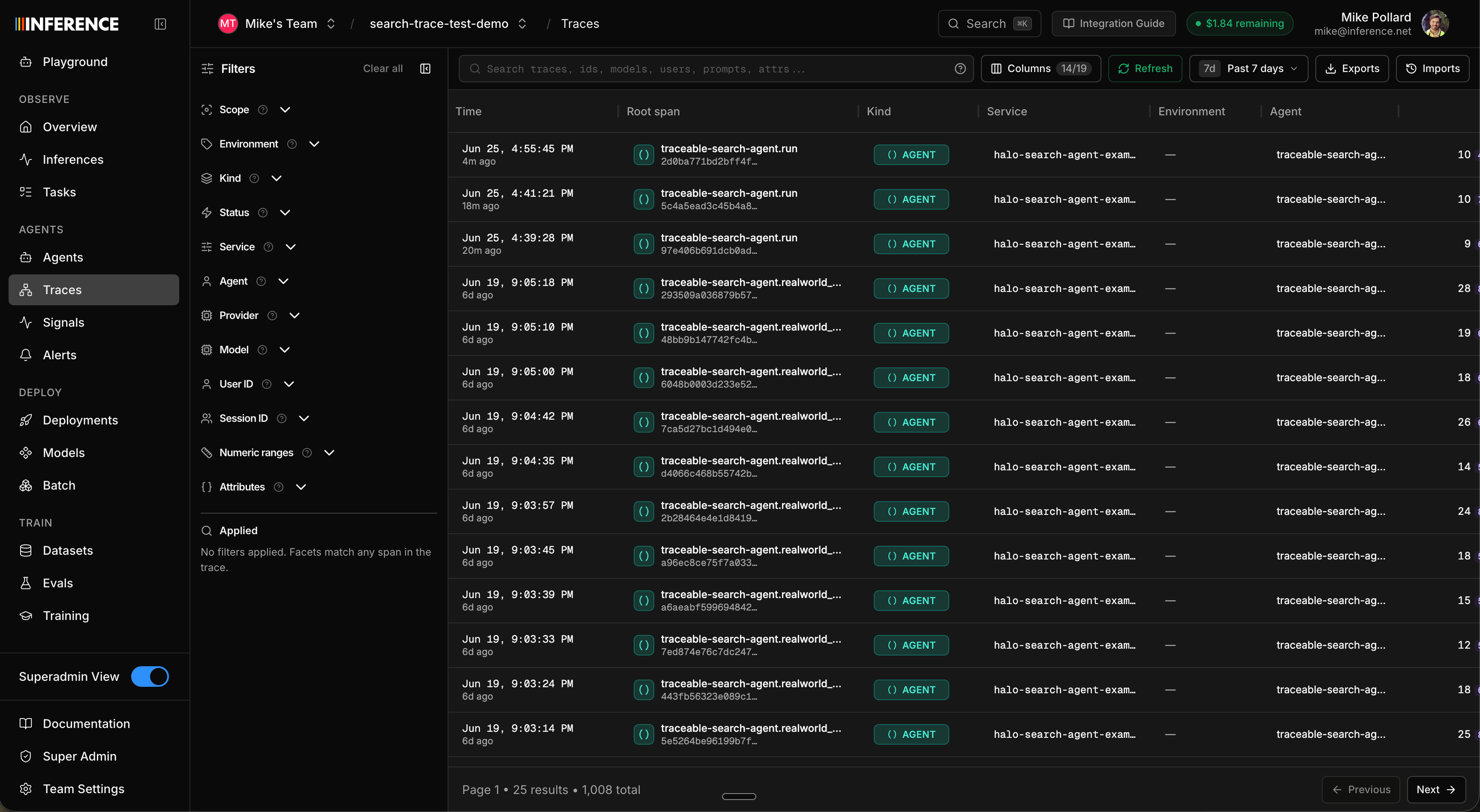
tavily.search and tavily.extract retriever spans nested underneath.
Step 5: Run HALO
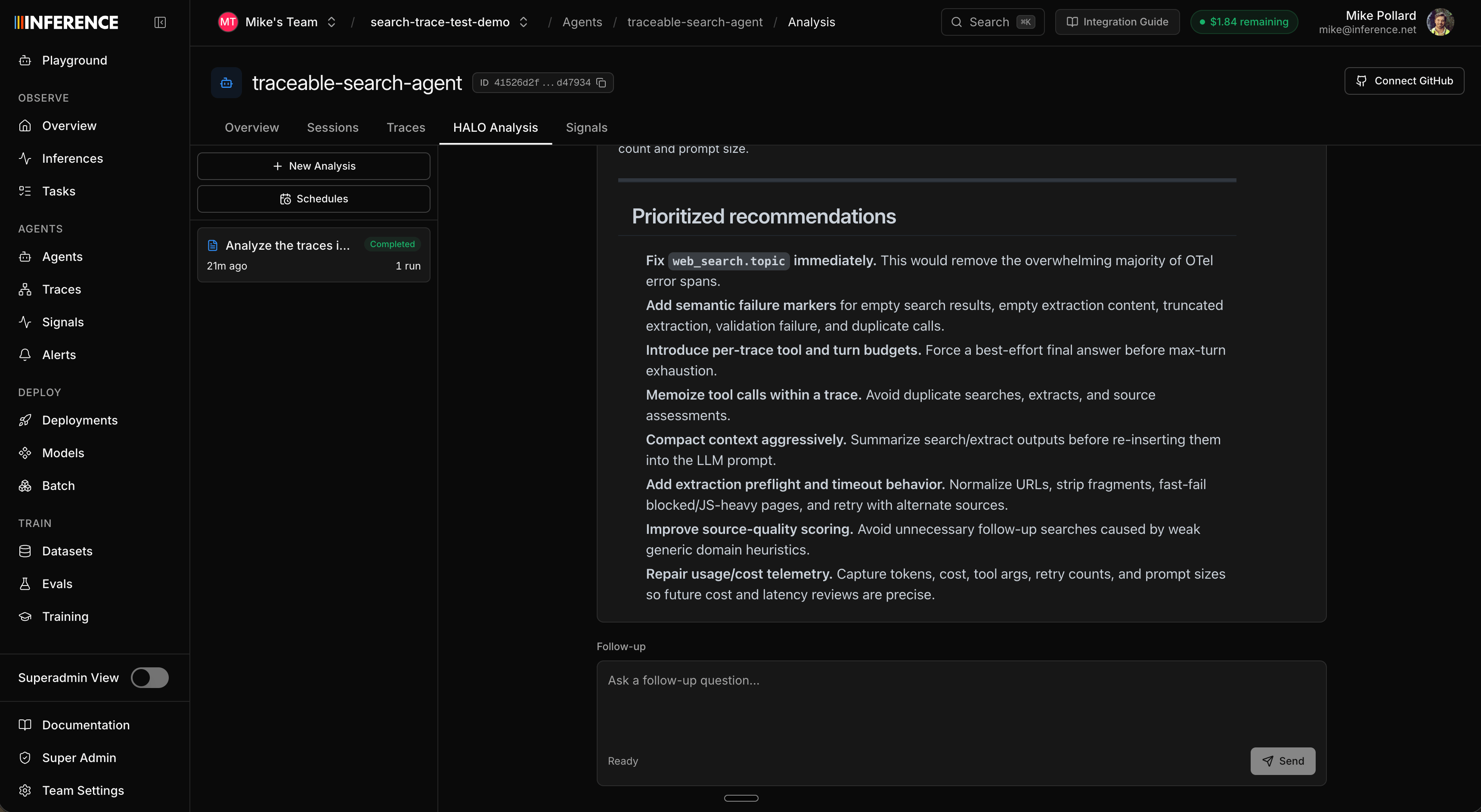
Open the agent’s Analysis sub-tab. This is the HALO workspace. There’s a prompt window on the right with a sensible default, plus a time-range picker and advanced options (span limit, max depth, max turns). Set the range to cover your traces and run it. If you uploaded the pre-run dataset, widen it to all time, since those traces keep their original timestamps. A tighter, more specific prompt gives sharper results. Because this repo has known weak spots, try aiming HALO at them: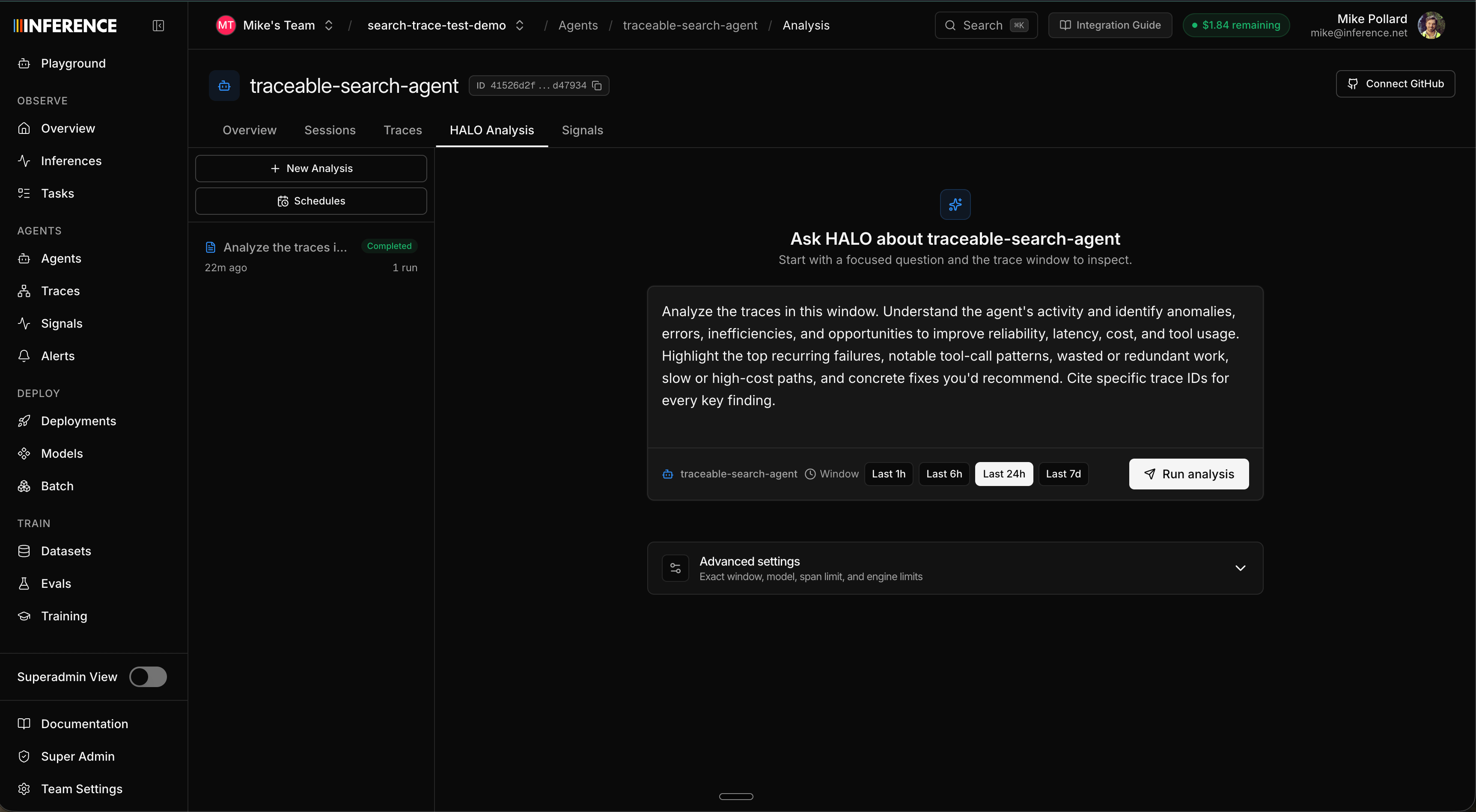
- Over-trusting the source-quality heuristic.
assess_sourcescores domains with simple rules and can overrate weak institutional pages. - A loose scratchpad. Notes are plain text with no schema, so stale or vague notes leak into the final answer.
- Shallow claim comparison.
compare_claimsonly checks lexical overlap, so it misses real contradictions. - Minimal deduplication. Repeated near-duplicate sources waste tool calls and bias synthesis.
- Truncated extraction.
extract_pagecaps content, so key evidence can fall outside the slice.
Optional: Connect your GitHub repo
You can connect your GitHub repo so HALO sees your actual code alongside your traces. With the source in hand, HALO grounds its findings in the real functions and prompts behind each trace and points to concrete fixes with real code examples, instead of reasoning from the traces alone. Once connected, HALO has access to the repo on every run and every follow-up question in the thread. For this demo it isn’t really necessary; the deliberate flaws show up clearly from the traces. But for a real repo full of agent code it makes a real difference, and we recommend it for sharper results.
Step 6: Connect the MCP server
This is the part worth doing slowly, because it’s where the loop closes itself. Connect the Inference MCP server to your coding agent so it can read your HALO reports and edit the cloned repo directly. The fastest setup, for Claude Code:.env.
Open your coding agent inside the repo you cloned so it can both read the HALO report (through the MCP) and edit the agent’s code (on disk).
Step 7: Apply the fix from your editor
Now just ask, in plain language:agent.py / agent.ts, the tool definitions in tools.py / tools.ts, the harness logic), grounded in the same findings you just read in the dashboard.
That’s the moment the loop closes itself: the traces you seeded got analyzed, turned into a ranked to-do list, and applied to the harness from a single line of natural language.
Step 8: Close the loop
A fix isn’t done until you’ve confirmed it worked, and confirming means new traces from the changed code, so this is the point where everyone generates their own runs, including if you took the upload shortcut in Step 3. The demo repo makes the comparison clean because the query set is fixed: run the same slice before and after and the only variable is your fix. (If you haven’t set up the repo yet, do Steps 1–2 first.)-
Run a slice of the bundled queries against your patched code.
--limit 5runs the first 5 of the 50 queries indata/queries.jsonl; keep it the same on both sides of the fix so the comparison is apples to apples: - Run HALO again over the new window (or set it on a schedule).
- Compare the two reports. The findings you fixed should be gone or diminished; pick up the next one.
context-labs/halo, MIT licensed). Read the engine and methodology, or self-host it and point it at your own exported traces.
Where to go next
Do this on your own agent
Run the same trace → HALO → fix loop against your real app. Start with
inf instrument --mode tracing.Measure agent quality with Signals
Turn the traces you seeded into quality metrics you can chart, filter, and get alerted on.
Connect the MCP server
Full setup and more example prompts for driving HALO from your coding agent.
HALO on GitHub
The open-source HALO engine, methodology, and benchmarks. MIT licensed.