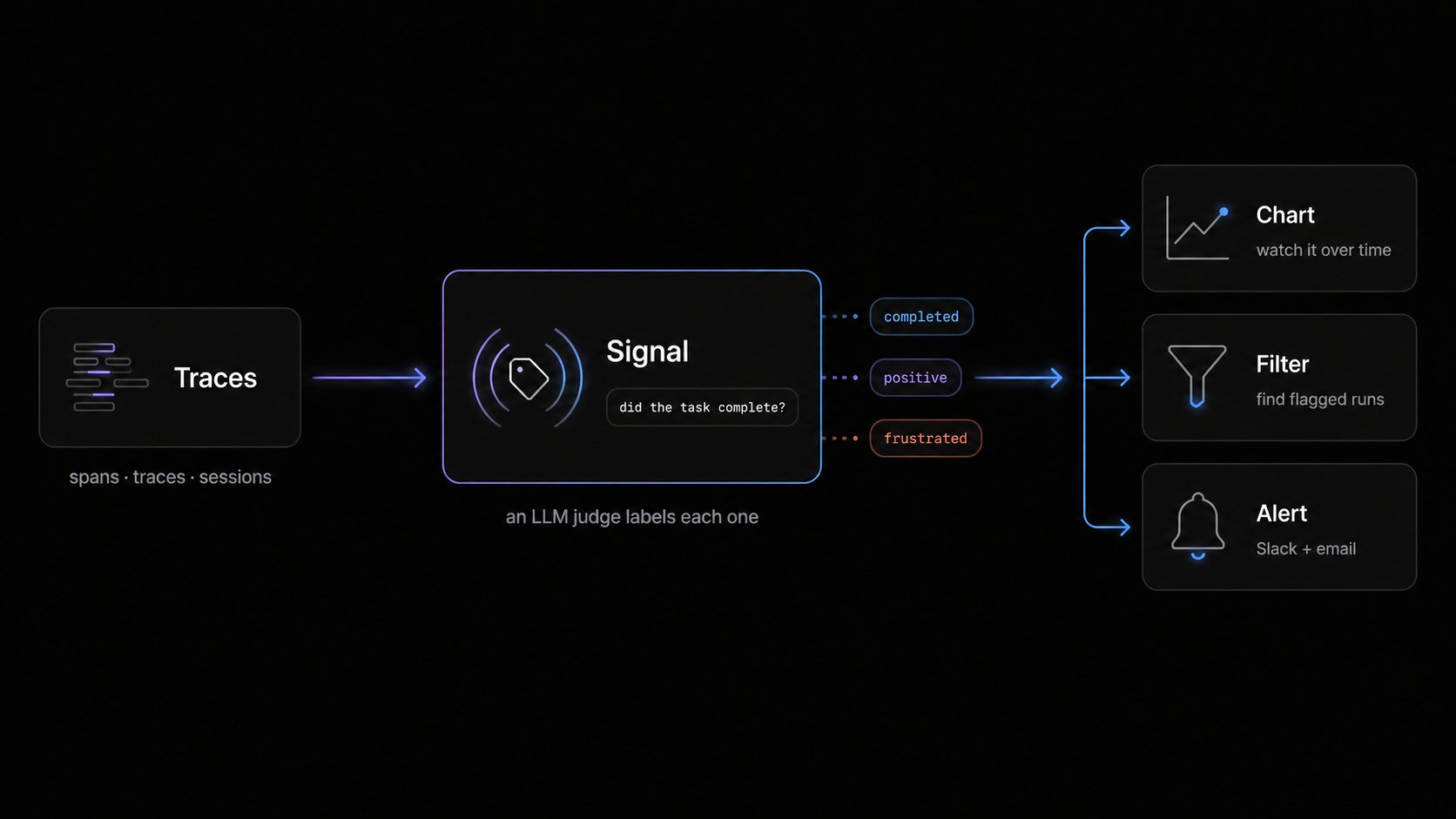
- How users interact with your agent — sentiment, frustration, jailbreak attempts, NSFW content.
- How your agent behaves — whether it completed the task, refused, or stalled.
inf signals). This guide leads with the dashboard.
Before you start
Signals run on your traces, so you need traces flowing first. You need:- A free Inference account.
- Tracing installed and traces arriving. If you haven’t done this, start with Optimize an Agent End to End or the Tracing Quickstart and come back once traces show up.
- A stable agent identity. Signals are scoped to one agent, so your runs need a consistent
agentIdto group on. If you instrumented with the CLI this is likely already set.
Signals group on
agentId. If you want session-scoped signals (Step 2), you also need a stable sessionId on your traces. See Agent identity.Step 1: Find Signals in the dashboard
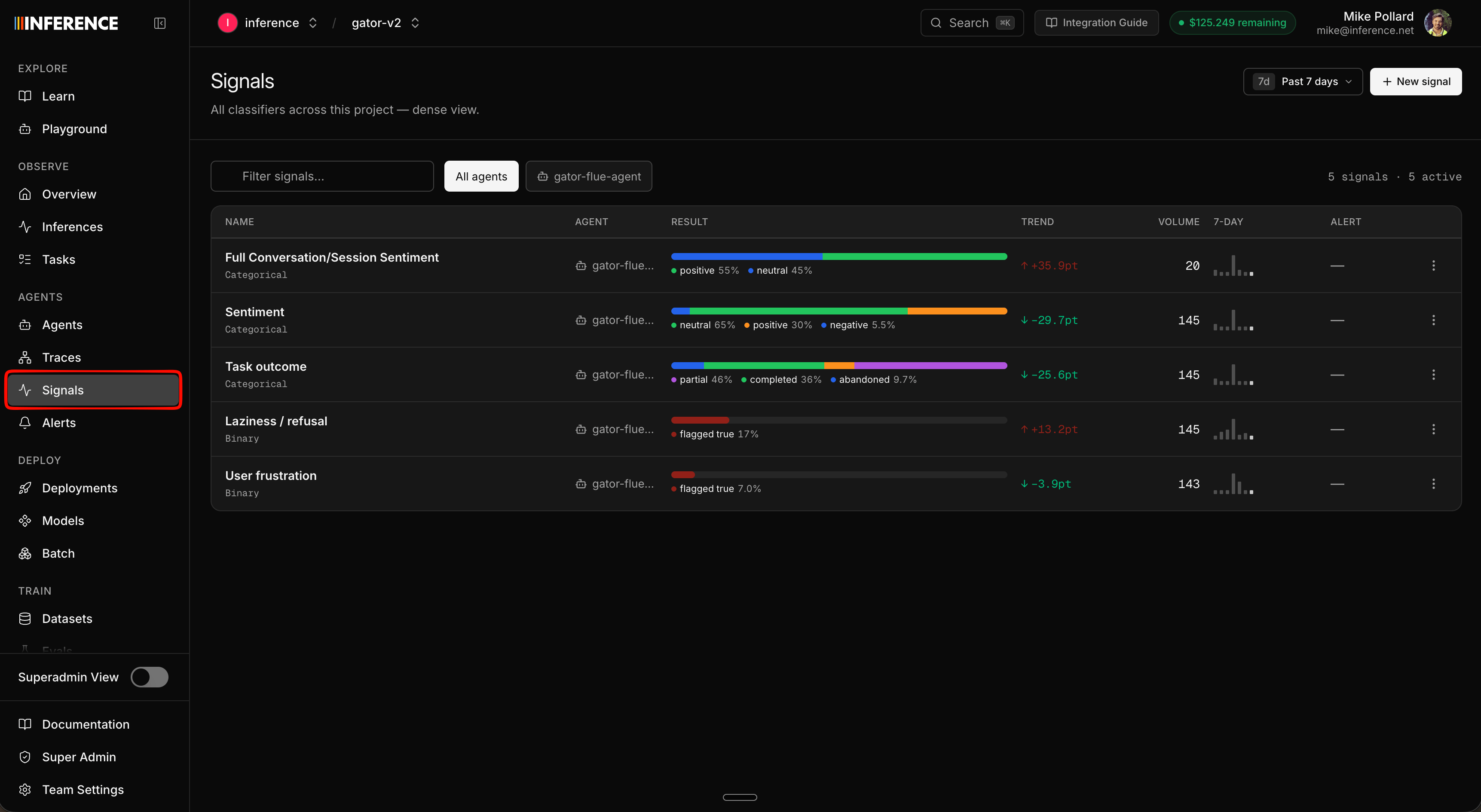
There are two ways in:- The top-level Signals tab lists every signal across all your agents in one table, with each one’s agent, scope, type, a live result breakdown, trend, and volume.
- Inside an agent (Agents → your agent → Signals) you see just that agent’s signals, with their overview graphs next to its other metrics.
agentId. Here’s the project-wide table for our team, with the spread we run on Gator:
Step 2: Create a signal
Open the agent’s Signals view and create a new signal. You can write your own from scratch or start from a template that prefills the type, prompt, and labels for a common case:
You’re not limited to these — write any prompt and classify anything you can describe. Either way, every signal comes down to a few decisions.
Classifier type
Binary (yes / no)
A true/false classifier for “is this X or not” questions: frustration, refusals, jailbreak attempts, NSFW. No labels to configure, just a prompt.
String (enumerated labels)
Returns one of a fixed set of labels you define. Use it when there are more than two outcomes: task outcome (completed / partial / failed / abandoned), sentiment (positive / neutral / negative). Define 2 to 10 labels.
Scope
A signal classifies one unit of traffic at a time:
The same question can be worth running at more than one scope. We track sentiment two ways on Gator: once per session for the overall vibe of a conversation, and again at a finer scope to spot where things turn. That’s why you’ll see both in the screenshots.
Sentiment
Every signal also carries a sentiment that tells Catalyst whether an outcome is good, bad, or neutral. This is what lets alerting reason about direction instead of just movement. A negative result trending up, or a positive result trending down, is worth flagging; a neutral result is just neutral and won’t trigger anything on its own. You set sentiment based on the classifier type:- Binary signals get one sentiment for the whole signal. A Jailbreak attempt or NSFW signal is negative, so any climb is bad news.
- String signals get one sentiment per label. On a Sentiment classifier you’d mark
negativeas negative,positiveas positive, andneutralas neutral, so a rise in negative labels or a drop in positive ones gets caught automatically.
Sample rate
A sliding selector sets how much of your matching traffic actually gets classified, anywhere from a small fraction up to 100%. Every classification is a judge call you pay for, so this is the main cost lever on a signal. 100% labels every span, trace, or session. That’s fine on a low-volume agent, but if you’re running a lot of traffic it’s usually far more than you need and can get expensive fast. A 25% or 50% sample gives you a representative trend at a fraction of the spend; raise it later once you trust the labels or want finer resolution. You can change it anytime.Write the prompt and save
Whatever you’re classifying, the prompt is the instruction the judge follows on every target, so be specific about what counts as each outcome (and, for a string classifier, what each label means). When it’s written, give the signal a short, readable name and save it as a draft — that keeps it unpublished so you can test before going live.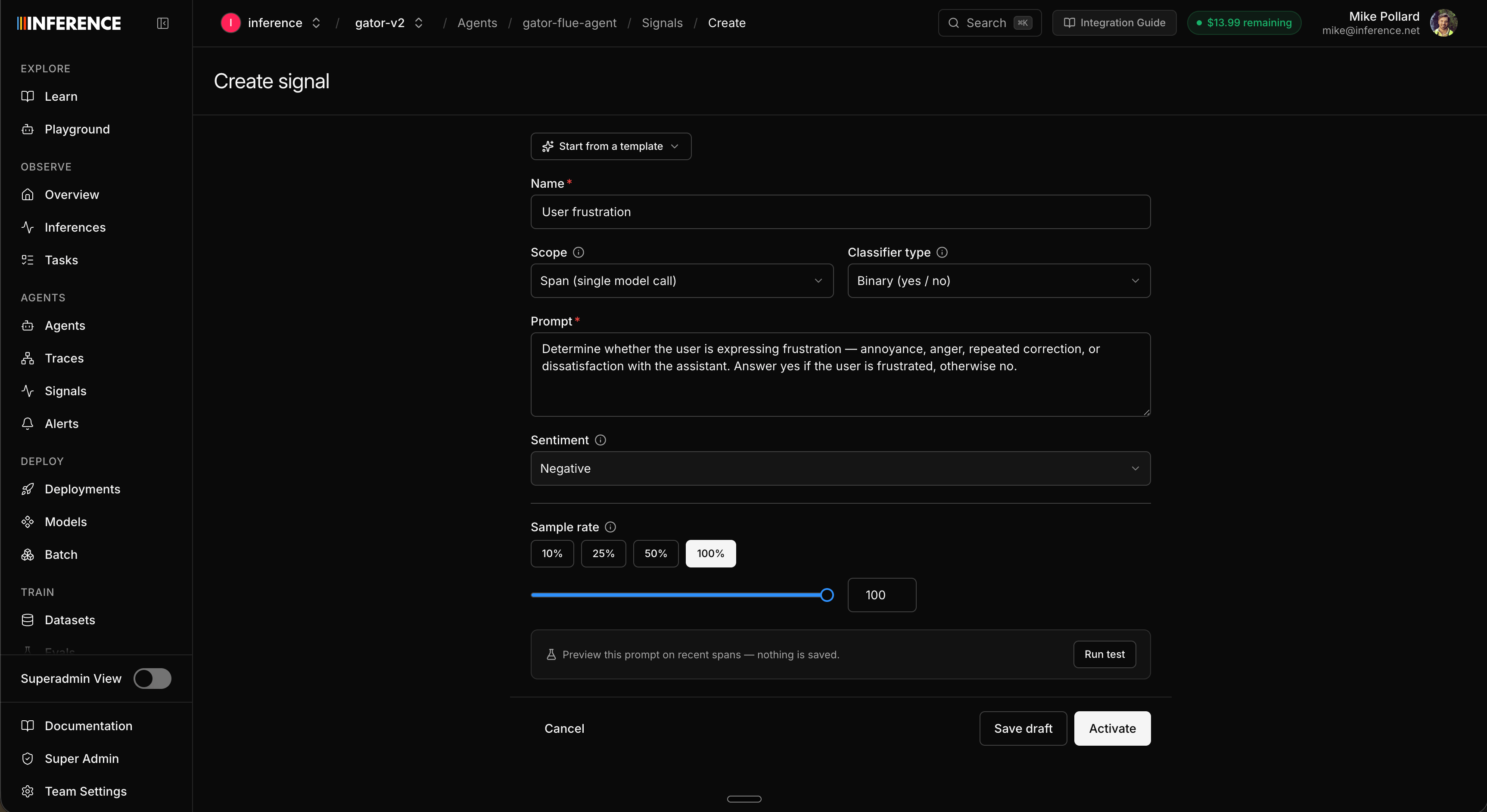
Step 3: Test before you activate
Before committing a signal to live traffic, run it against recent data to preview how it labels. A test classifies a small sample (1–100 recent targets) and shows you the distribution plus the label on each one. Nothing is saved — it’s a preview, so it doesn’t touch your signal or store labels. If the judge disagrees with you on a few, tighten the prompt and test again. This is the cheapest place to get a signal right, before any labels exist.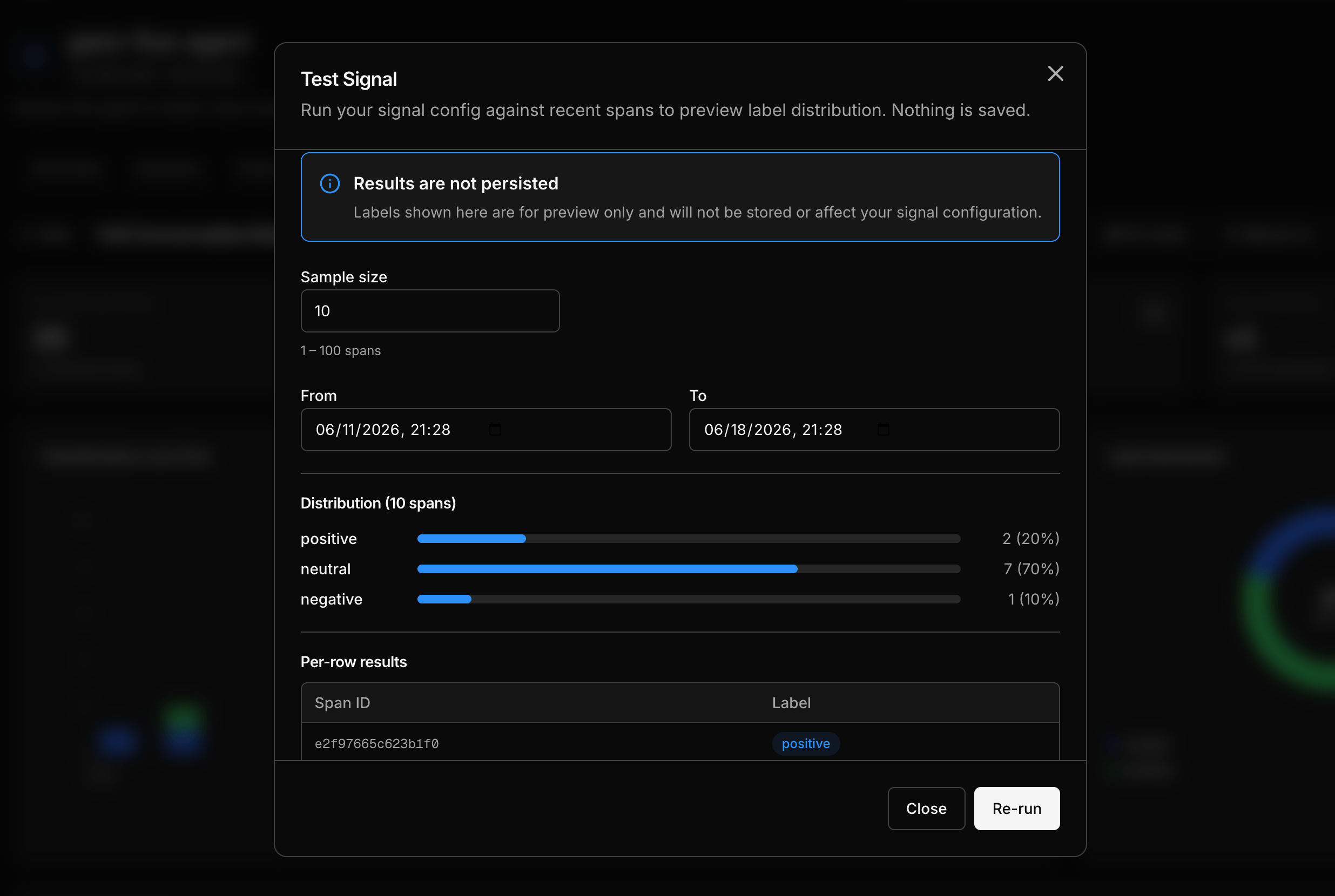
The CLI equivalent is
inf signals verify.Step 4: Activate, pause, and resume
When the test looks right, activate the signal. Live classification starts immediately: as new traffic arrives, the configured share is sampled and labeled automatically. A signal is always in one of three states, and you can move between them anytime:
Pause an active signal whenever you want and resume it later without losing history. Sampling is deterministic, so the share you set is the share you pay for.
Step 5: Backfill historical data
Live classification only labels traffic that arrives after you activate. To label data you already captured — so your charts have history on day one — run a manual run (backfill): pick a historical window and a sample rate, and it classifies past targets in the background. Unlike a test, a backfill saves its labels, exactly like live ones. You can run one at any point, not just at creation.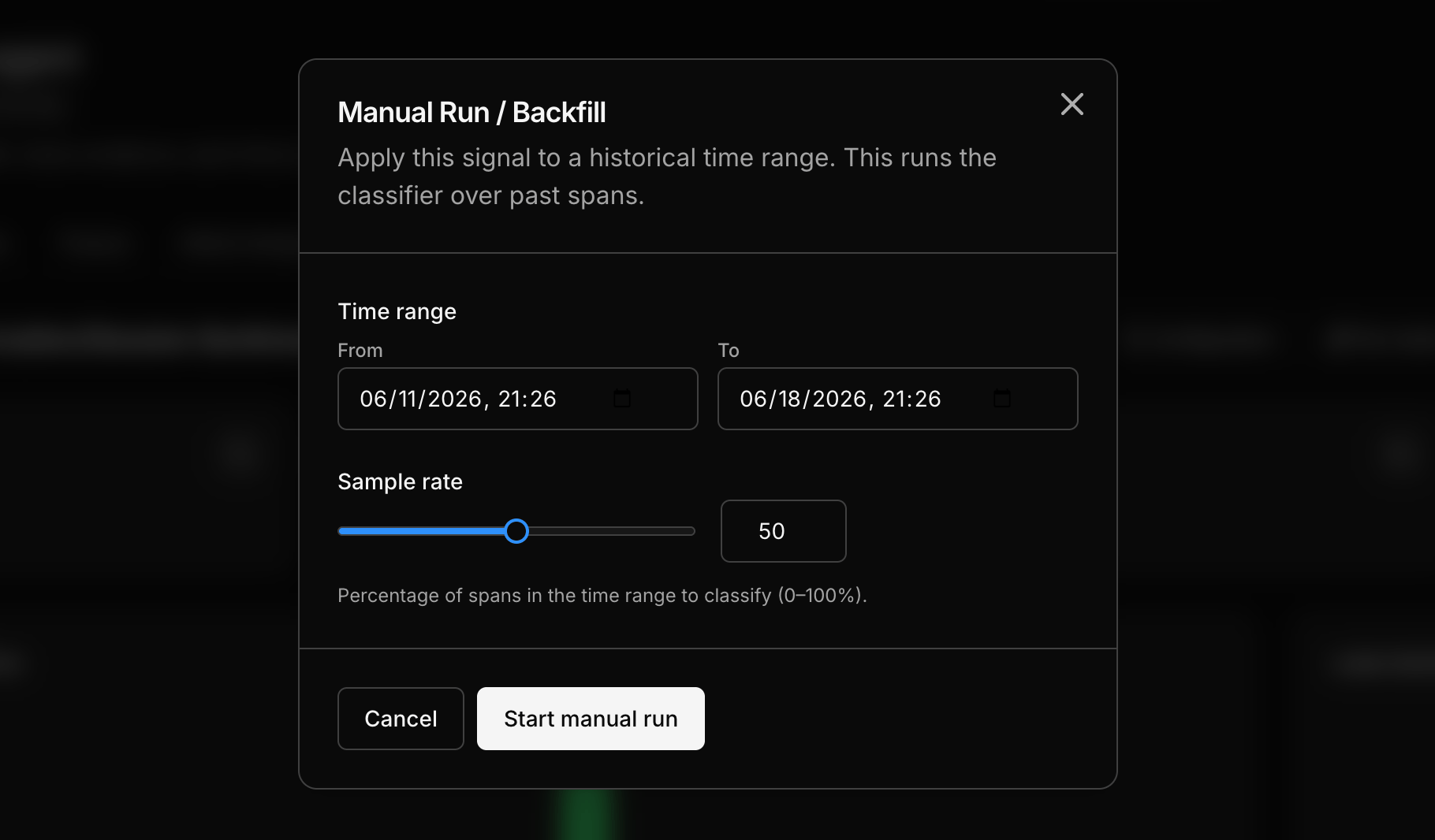
Step 6: Read the results
This is where signals become metrics. Each agent’s Signals view rolls up every signal it runs: a summary up top (how many are active, total classifications, the busiest signal) and a card per signal with its label breakdown and trend, sitting right next to run count, latency, and cost.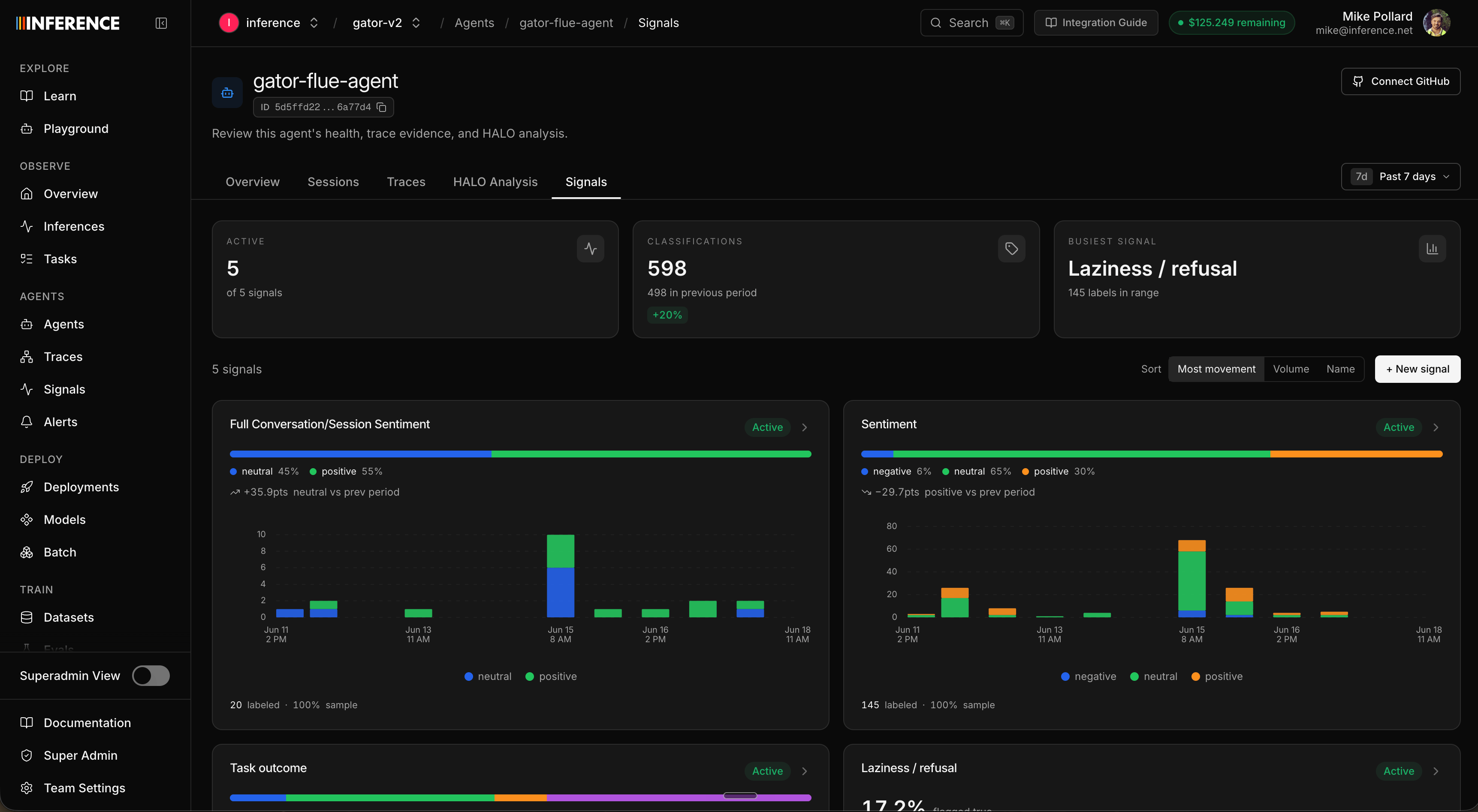
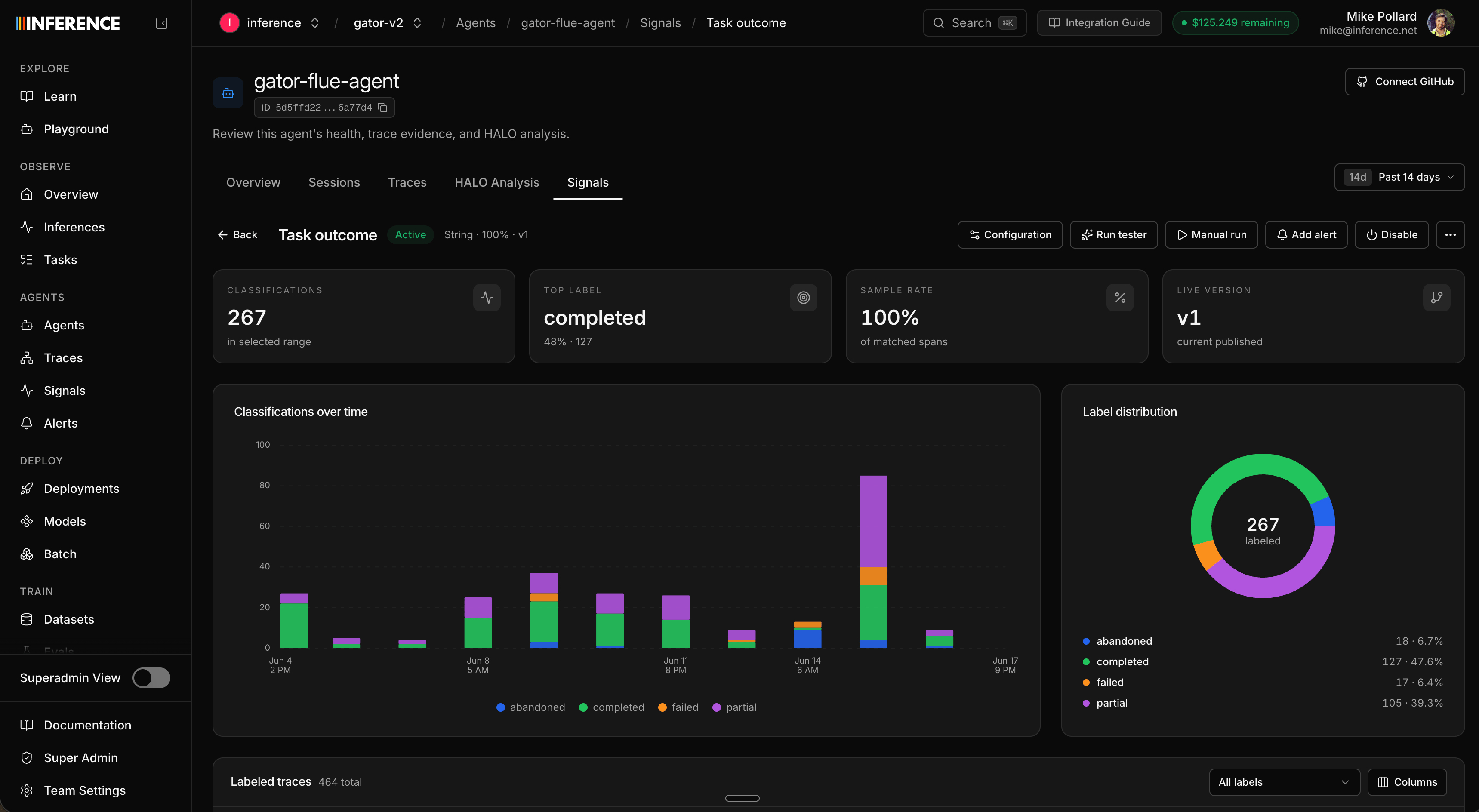
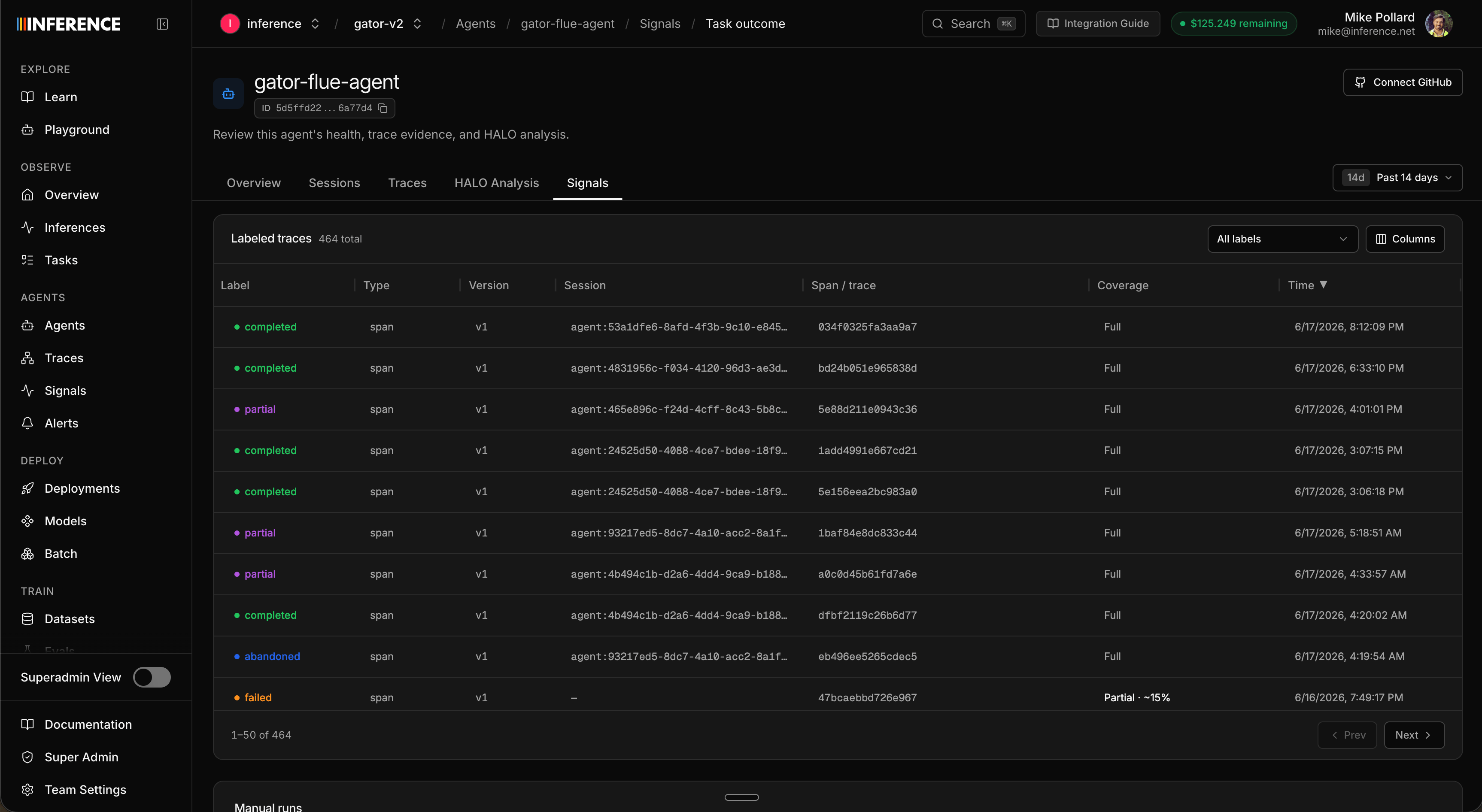
Step 7: Edit and version
Editing a signal’s prompt, labels, or sample rate creates a new version rather than overwriting the old one. The dashboard shows each version, and every label records which one produced it, so you can sharpen a definition over time without losing the history of what earlier versions decided. (Scope is the one thing fixed at creation.) When a signal has served its purpose, archive it: it stops and leaves your active list, but its labels are preserved.Step 8: Get notified
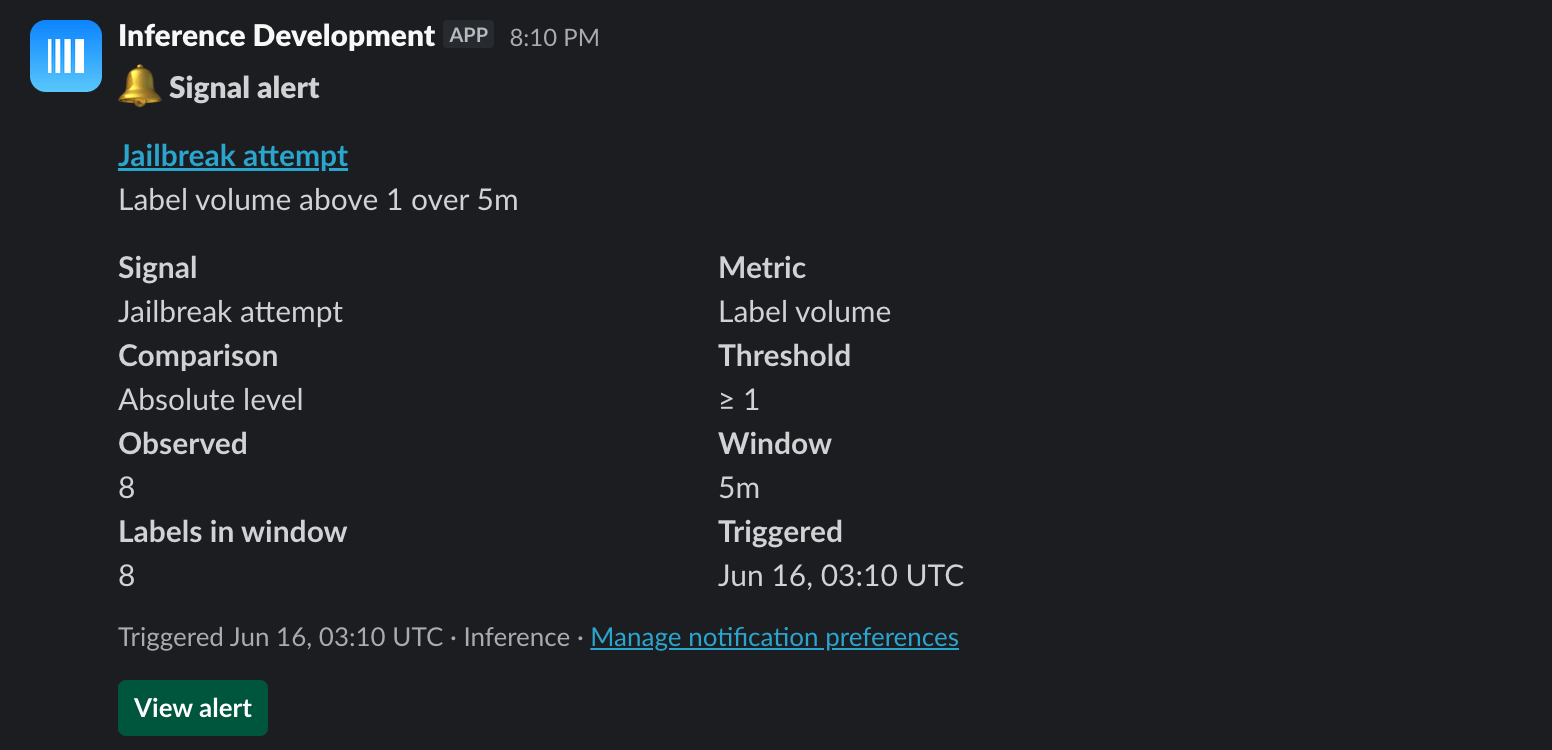
A trend you have to remember to check is one you’ll miss. There are two ways to stay on top of your signals without logging in: targeted alerts for a specific condition, and a daily overview that summarizes everything.Targeted alerts
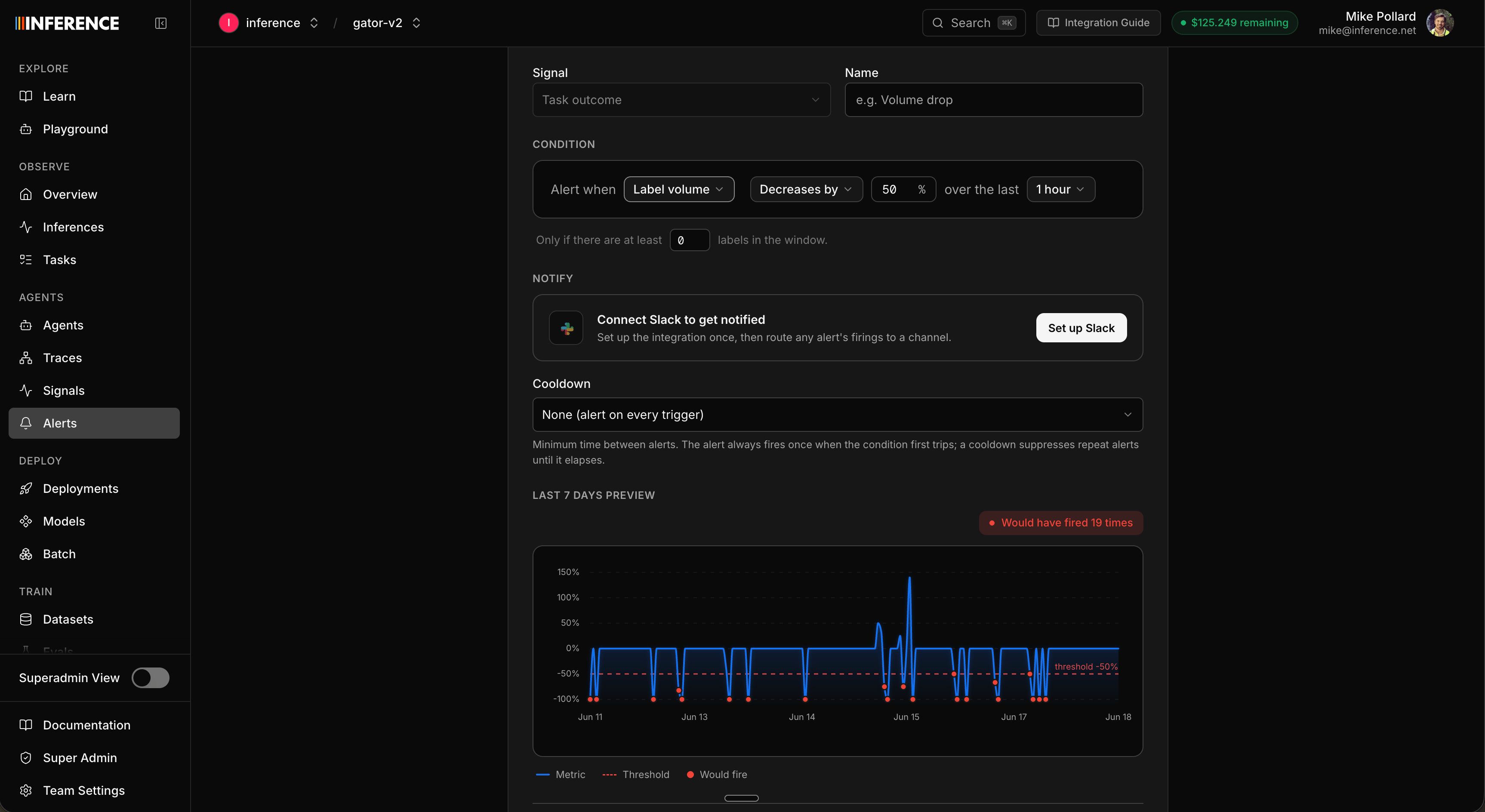
An alert watches one signal and fires when its numbers cross a line. They’re configured per signal (a signal can have several), and a global Alerts page lists every alert across all your signals. You build an alert by picking a metric to watch, the direction and threshold that count as a problem (a level it crosses, or a percentage it moves up or down), and the time window to measure over. Which metrics are available depends on the signal’s type:
The threshold reads one of two ways: percentage change (the metric moves up or down by X% versus the prior window) or an absolute level (it crosses a fixed number). You also set the rolling window (5 minutes to 48 hours), an optional minimum label count so low volume doesn’t trip it, and a cooldown so repeat firings don’t bury you. As you tune it, the form previews where the alert would have fired over the last 7 days.
The sentiment you set in Step 2 is what makes the direction obvious here: you watch negative labels for an increase and positive labels for a decrease, since both mean things are getting worse. Neutral labels are rarely worth alerting on at all.
Daily overview
Targeted alerts are for when something specific goes wrong. The daily overview is for confirming everything’s humming along without opening the dashboard. Opt in and you get a once-a-day email (or Slack) summarizing all your signals: how many were classified, and the biggest movers since yesterday. It’s the “is anything off?” glance you can do from your inbox.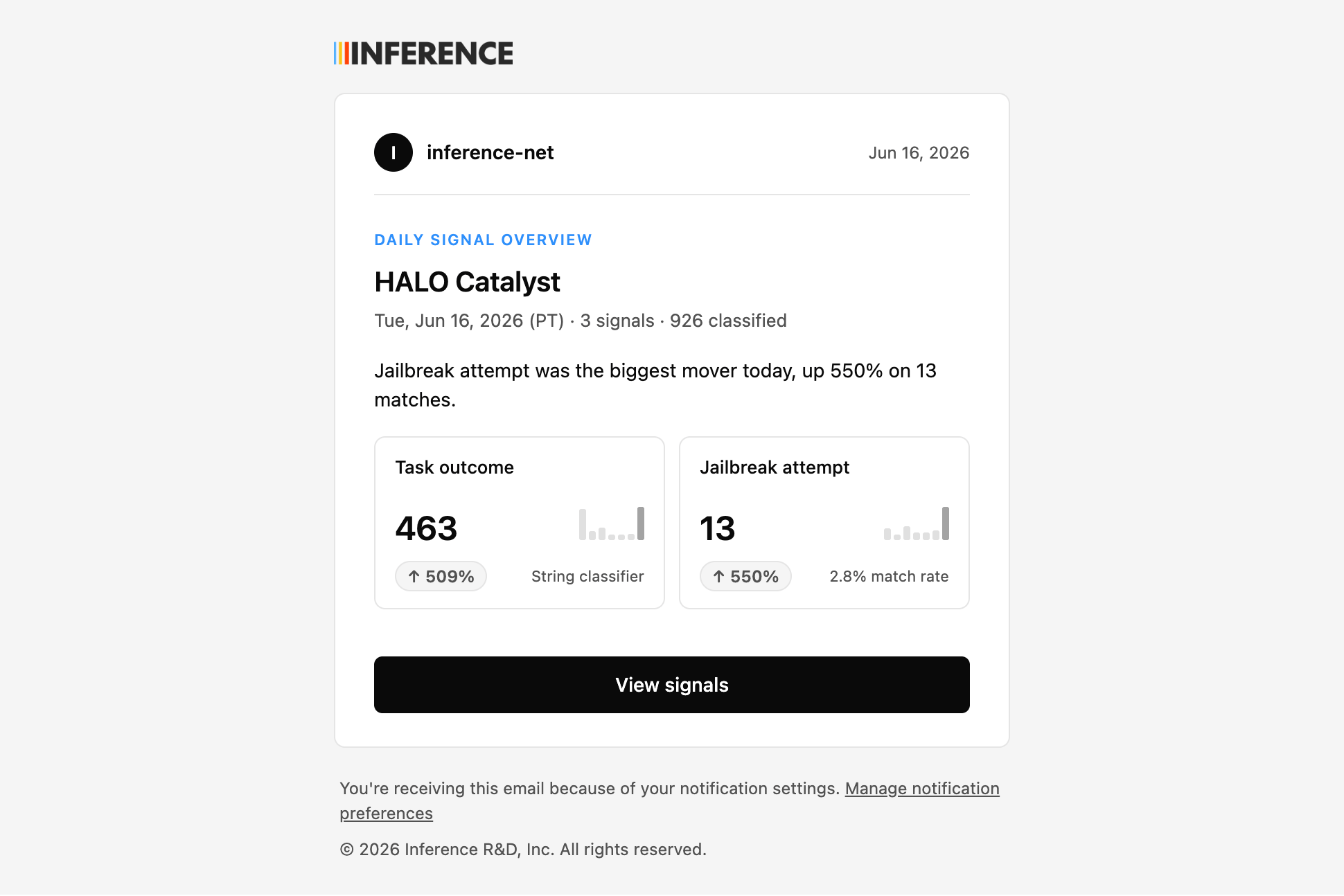
Step 9: Hand it to HALO
Signals tell you what is happening and how often — failed tasks spiked overnight, frustration is up this week. HALO tells you why, and what to change. The handoff runs through the MCP server. With Inference connected to your coding agent, you go from a signal to a fix in plain language:Where to go next
You now have quality metrics that didn’t exist an hour ago — defined in a sentence, computed on every run, charted, and wired to notifications — with no extra instrumentation.Signals reference
Full reference for classifier types, scopes, sample rates, states, testing, backfills, and templates.
Optimize an agent end to end
Run HALO on the traces your signals flag to find the root cause and apply the fixes.
Try HALO on a demo repo
Run the full trace → HALO → fix loop on a ready-made instrumented agent in about fifteen minutes.
Connect the MCP server
Create signals, read labels, and hand flagged traces to HALO from your coding agent.
Set agent identity
Add stable agent and session IDs so signals attach to the right agent and scope cleanly.