The Real-World Problem
Large frontier models already know how to do your task, but running them in production can be painfully slow and expensive. Distillation fixes that.| Step | What Happens | Why You Care |
|---|---|---|
| 1. Fine-tune a teacher (pick any strong open-source or proprietary checkpoint). | We make the model excellent on your task, no compromises. | Accurate. |
| 2. Distill that teacher into a smaller student (7-27 B). | The student learns by copying the teacher’s answers. | 5-10× faster & cheaper. |
3. Deploy the student behind the same /chat/completions endpoint. | Zero code changes besides the model name. | Straight to prod. |
You don’t need labeled outputs.
Provide a pile of inputs (dog images, video frames, customer emails).
The teacher generates the supervision signal; the student learns from it.It’s possible you already have users passing in data to a large, overly expensive LLM. We can just use that data to fine-tune the model!
Provide a pile of inputs (dog images, video frames, customer emails).
The teacher generates the supervision signal; the student learns from it.It’s possible you already have users passing in data to a large, overly expensive LLM. We can just use that data to fine-tune the model!
When to Reach for Distillation
| Use-case | Why Distill? |
|---|---|
| Image or video tagging | Teacher handles vision; student runs on a single GPU for nightly batches. |
| High-volume classification | 10 K requests/sec without burning $$. |
| Strict JSON / XML extraction | Student stays inside schema; latency drops below 100 ms. |
| Edge deployment | Fit a 7 B model on CPUs or mobile, no external API call. |
Rule of thumb: If the teacher nails quality but misses your latency or cost SLO, distill it.
What Distillation Looks Like
Here’s model an example of a model training run where we distilled a 27B model into a 12B model. Notice that the distilled model was effectively able to learn the same task as the teacher model, but at a fraction of the cost and latency. We first fine-tuned the teacher model on a set of 100k examples passed through Gemini-2.5-Pro. Then we distilled the teacher model into a 12B model. The distilled model was able to learn the same task as the teacher model, but at a fraction of the cost and latency!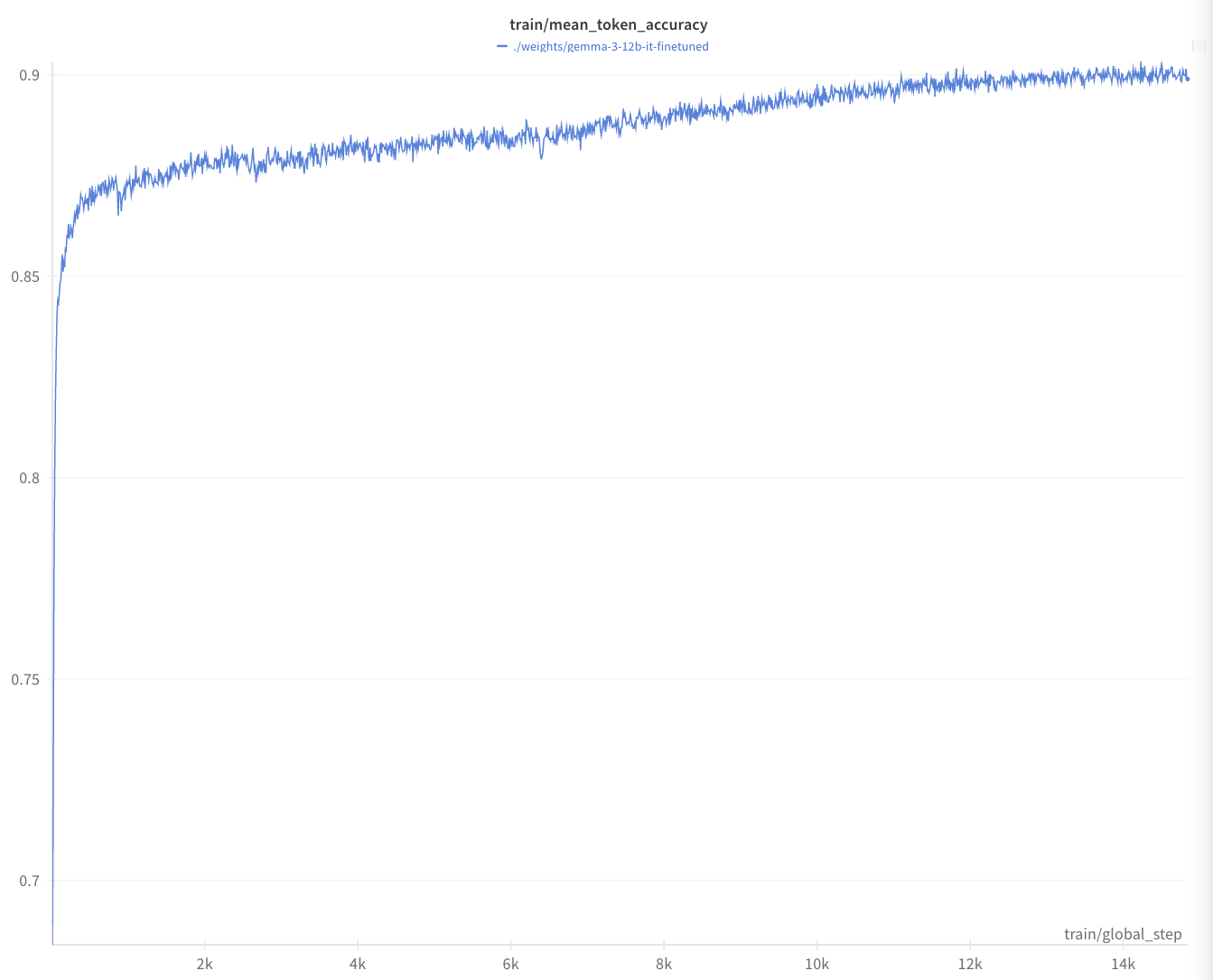
- Gemma 27 B teacher (fine-tuned) vs Gemma 12 B student
- ∼90 % token accuracy (student) at ~4× speed and 1/3 memory
- Runs on a single A100 instead of eight H200s
Modalities
| Modality | Example Tasks |
|---|---|
| Text → Text | Code completion, instruction following, data extraction |
| Image → Text | Captioning, classification, tagging |
| Video → Text | Captioning, Q&A, summarization |
| Audio → Text | Transcription, Q&A (often with video) |
What Happens Next
- Scoping call – goals, latency SLO, data hand‑off.
- Our experts fine-tune and deploy your custom model.
- Validation report – accuracy, latency, cost projections.
- Production endpoint – isolated, autoscaled, monitored.